[기계학습 심화] PCA
Supervised Learning vs Unsupervised Learning
- Supervised Learning: 지도 학습
- 데이터에 레이블이 붙어 있음
- 예측 문제 (Regression, Classification)
- 예시: Linear Regression, SVM, KNN
- Unsupervised Learning: 비지도 학습
- 데이터에 레이블이 없음
- 군집화 문제 (Clustering)
- 예시: K-Means, PCA

PCA (Principal Component Analysis)
Unsupervised Learning 기법으로
머신러닝, 딥러닝 할때 데이터 크기 (차원)이 너무 크다는 문제점을 해결하기 위해 사용하는 것이다.
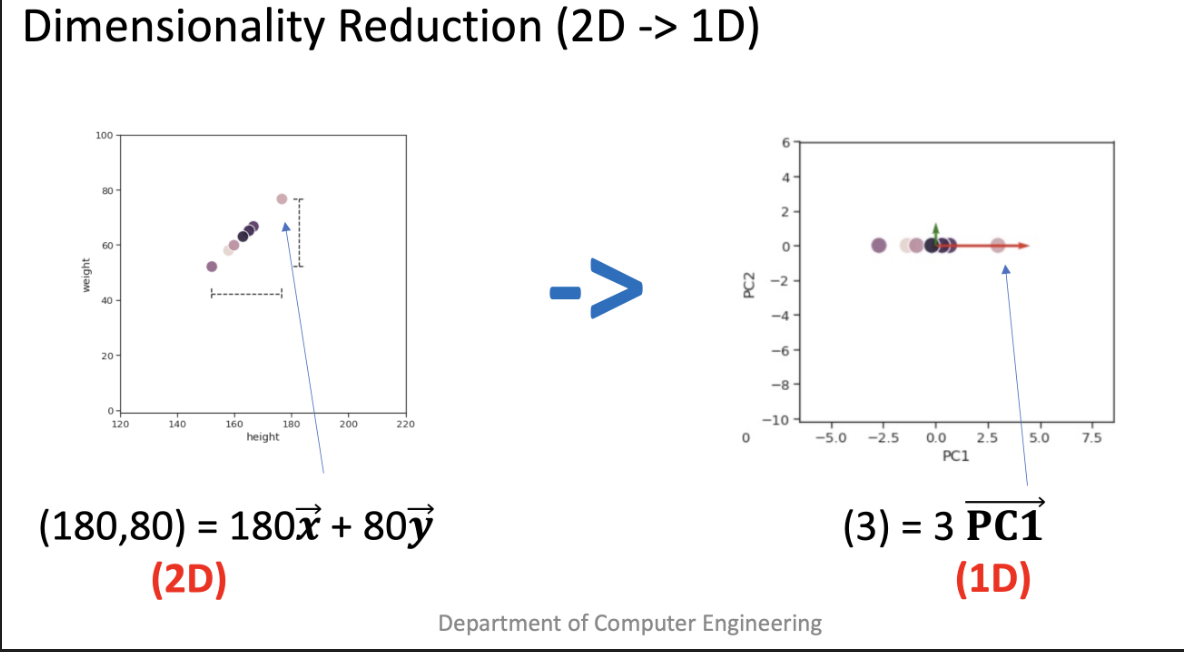
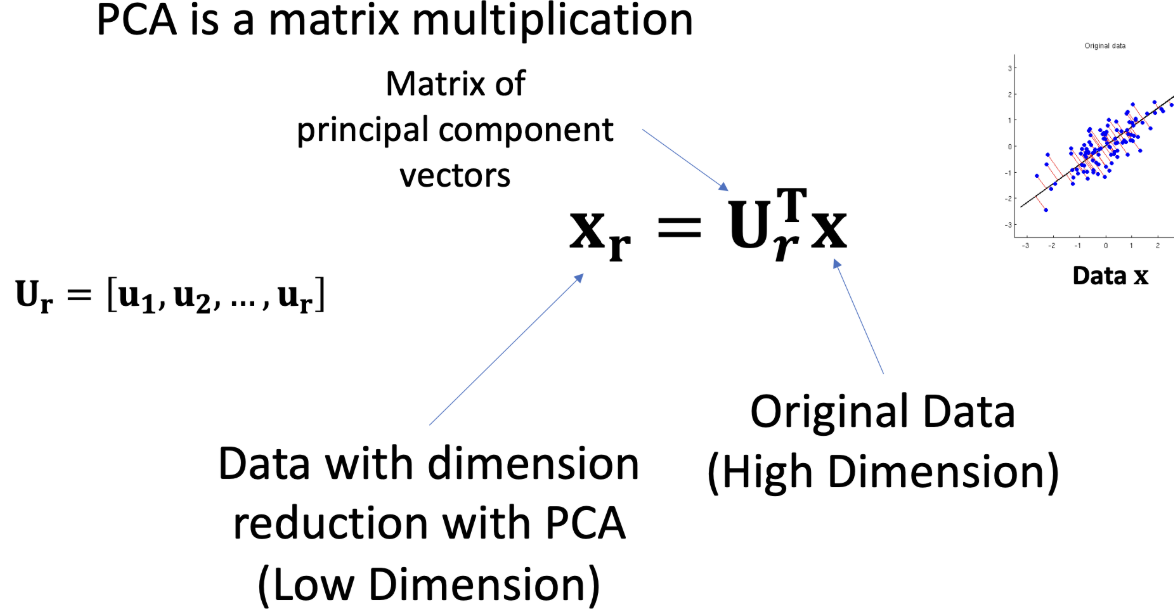
쉽게 말해 축 (basis vector)를 바꿔서
차원을 줄이는 방법이다.

실질적으로는 새로운 축에 완전히 정렬 되어 있지 않았을 텐데,
완벽하게 새로운 축에 정렬 되어 있지 않은 경우도 조금의 차이는 무시해서 차원을 줄이자는 아이디어.
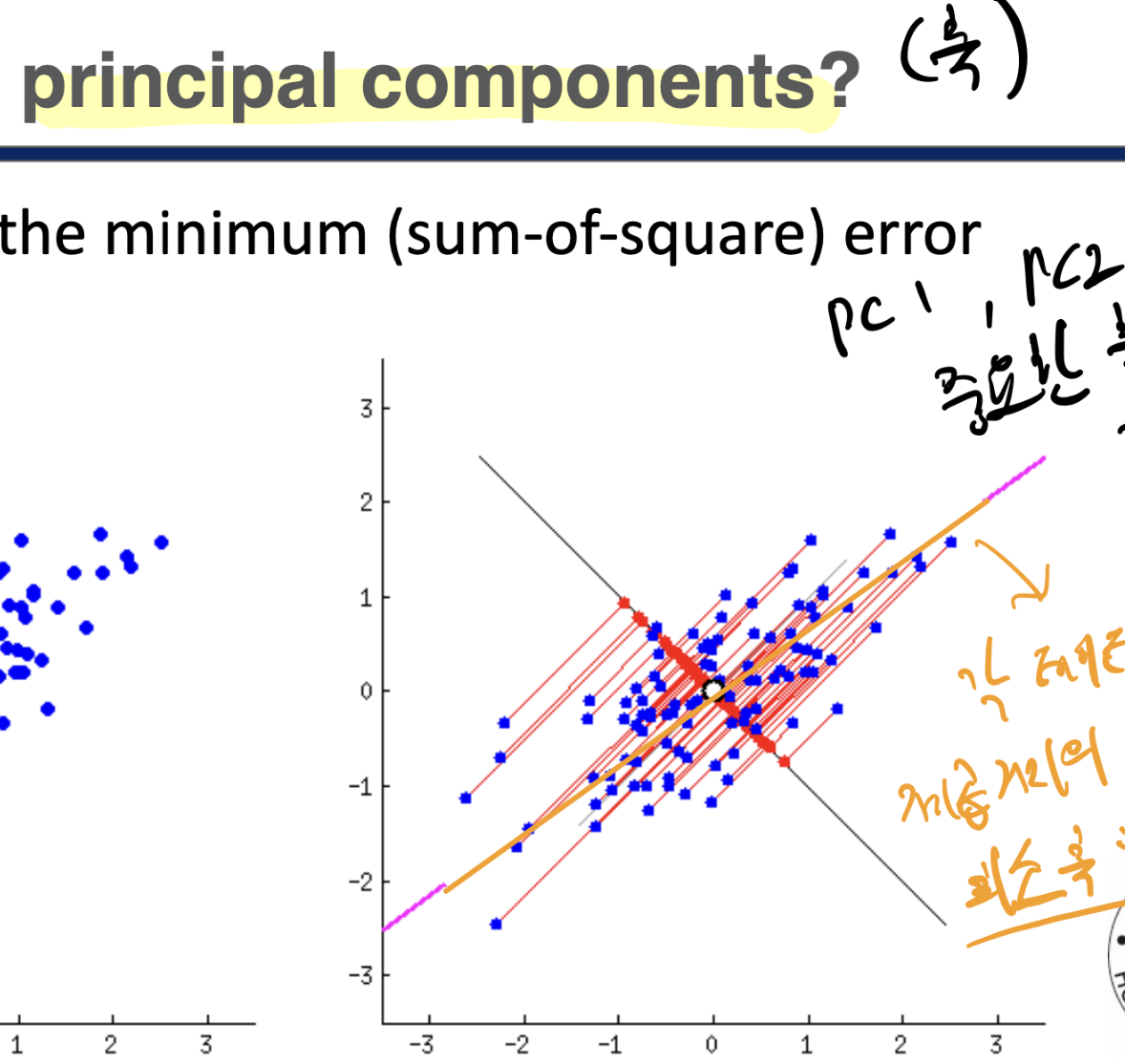
실질적으로 principal component(축)을 찾는 방법은 직교하는 나머지 값 제곱거리가 최소가 되는 축을 찾는다..
그 수학적 방법론이 SVD(Singular Value Decomposition)이다.
축을 찾은 뒤에는 축과 기존 좌표를 내적해서 새로운 기준의 좌표를 구할 수 있다.
예를들어
100만 차원의 데이터를 1000차원으로 줄이고 싶다면
1000개의 축을 찾고
1000개의 축과 기존 좌표를 내적해서 새로운 좌표를 구하면 된다.
(1000개의 축을 찾는 방법은 SVD)
성능
KNN에 PCA를 적용했을 때 성능을 비교해보자
import random import matplotlib.pyplot as plt
from keras.datasets import mnist
X_test = test_X.reshape(10000,784).astype(float)
y_train = train_y
y_test = test_y
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors= 5, p = 2) clf.fit(X_train, y_train)
pred = clf.predict(X_test)
print("Accuracy: ", accuracy_score(y_test, pred))
from sklearn.decomposition import PCA
pca = PCA(n_components = 10,svd_solver= 'full')
pca.fit(X_train)
ced = pca.transform(X_train)
X_test_reduced = pca.transform(X_test)
clf= KNeighborsClassifier(n_neighbors= 5, p = 2) clf.fit(X_train_reduced , y_train)
pred = clf.predict(X_test_reduced)
print("Accuracy: ", accuracy_score(y_test, pred))

성능은 조금 내려가지만
data size가 많이 줄어서 실행 시간이 약 60배 빨라졌다.
데이터 size는 약 80배 줄어들었다.
(784 -> 10)

장단점

성능은 위에서 확인했고

노이즈를 줄여주는 효과가 있다고 한다.
단점으로는 경향성이 없는 경우
데이터를 잘 설명하지 못할 수 있다.
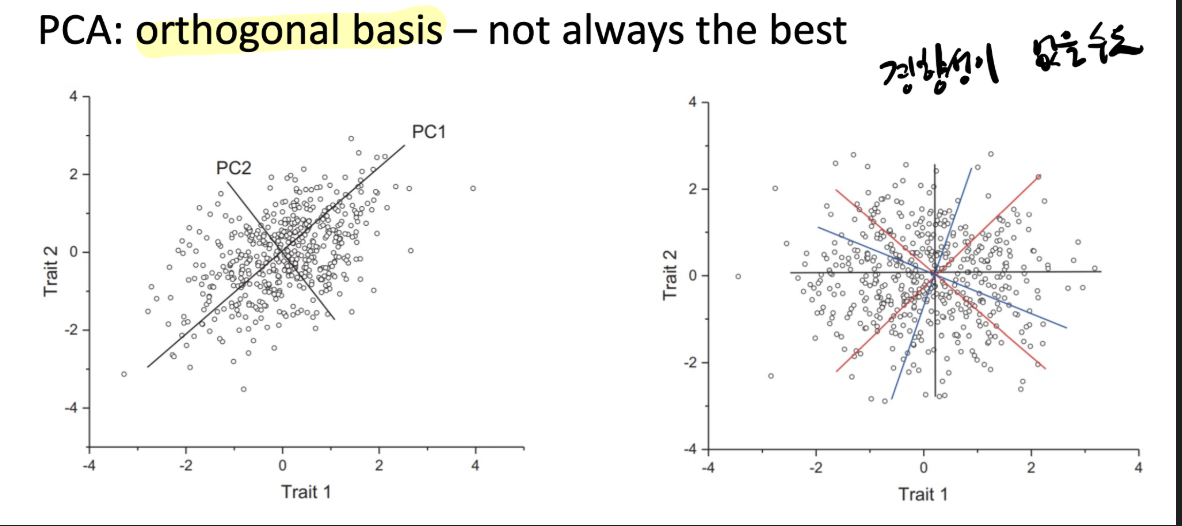
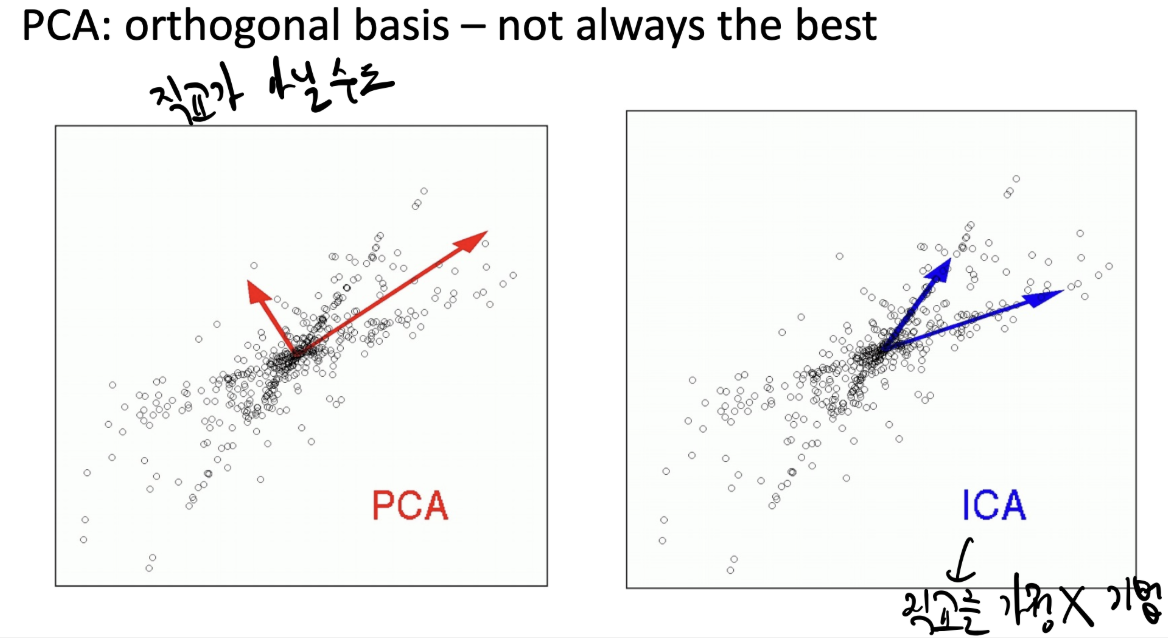
이럴때는 ICA (직교를 가정하지 않는 방법)를 사용하면 된다고 한다.